Dynamische Webseiten mit PHP
Datenbanken
Entwicklung der Datenbanksysteme
Die Entwicklung der Datenbanksysteme ist eng an die der Hardware gekoppelt und wird wie jene in Generationen eingeteilt:
1. Generation: In den fünfziger Jahren waren die wesentlichen Ein- und Ausgabegabemedien für große Datenmengen Papier und Magnetbänder. Da beide Medien ausschließlich sequentielle Verarbeitung zulassen, gab es in dieser Generation nur den sequentiellen Zugriff auf die Datensätze einer Datei.
2. Generation: In den frühen sechziger Jahren konnten die Rechner erstmalig im Dialog-Betrieb genutzt werden und durch den Einsatz schneller, wahlfreier Speichermedien wie Magnetplatten war ein direkter Zugriff auf einzelne Datensätze möglich. Den Datensätzen wurde dazu eine Adresse zugeordnet, die dann mittels Indexdatei oder Hashfunktion ermittelt wurde. In beiden Generationen bestand eine starre Zuordnung zwischen Datei und Anwenderprogramm.
3. Generation: In dieser Generation (etwa 1965-1975) wurde die Unterscheidung zwischen logischen und physischen Informationen aufgehoben, die dann nicht nur verarbeitet, sondern auch verwaltet wurden. Damit war eine gemeinsame Nutzung der Dateien und verschiedene Sichten auf die Daten möglich.
4. Generation: Die Systeme dieser Generation (1975 bis ca. 1990) trennen klar zwischen dem physischen Datenmodell (insbesondere der Einmalspeicherung der Daten zwecks zentraler Verwaltung) und dem logischen Datenmodell, wie es in dem relationalen Modell am weitesten entwickelt ist. Diese Datenbanksysteme werden im Drei-Ebenen-Konzept (s.u.) dargestellt.
5. Generation: Objektorientierte Datenbanken (neunziger Jahre)
In objektorientierten Datenbanken werden die Daten in Objekten modelliert. Damit sind spezielle Verarbeitungen möglich, die in den früheren Strukturen nur sehr aufwendig realisiert werden konnten (z.B. Vererbung).
Vorteile einer Datenbank
| • | Redundanzfreiheit Die Daten treten in der Datenbank nur einmal auf. Damit wird eine erhebliche Reduzierung des Änderungs- und Speicheraufwands erreicht. Aus Effizienzgründen wird in Datenbanken manchmal mit Redundanz gearbeitet, die dann allerdings zentral durch das DBMS kontrolliert wird. |
| • | Vielfachverwendbarkeit Verschiedenen Benutzern mit unterschiedlichen Anforderungen können auf dieselbe Datenbank zugreifen. Es sind also verschiedene Sichten auf den selben Datenbestand oder Auszüge daraus möglich. |
| • | Datenunabhängigkeit Die vom Benutzer gewünschte Datenstruktur ist unabhängig von der physischen Struktur. |
| • | Programmunabhängigkeit Die Anwenderprogramme sind datenunabhängig, d.h. bei Änderung der Organisationsform der Datei müssen die Programme nicht angepaßt werden. Ausserdem ist die Nutzung verschiedener frondend (PHPMyAdmin, CocoaMySQL, MySQLFront etc.) für die selbe Datenbank möglich. |
| • | Datenkompatibilität Durch die Festlegung der Datenstruktur (CSV, SILK etc.) wird die Mehrfachverwendung und der Datenaustausch begünstigt. |
| • | Integrität, Konsistenz Unter Integrität versteht man die Korrektheit und Vollständigkeit der abgespeicherten Daten. Die Verwaltung der Daten durch das DBMS ermöglicht Kontrollroutinen bei der Aufnahme neuer oder Änderung alter Daten und zur regelmäßigen Überprüfung (Recovery) des bestehenden Datenbestandes. |
| • | Datensicherheit Schutz vor Verlust und Verfälschung der Daten und vor unberechtigtem Zugriff auf die Daten. |
Datenorganisation und Begriffe
| • | Hierarchische Datenorganisation (Buch-Kapitel-Absatz) |
| • | Netzwerk-Organisation (WWW) |
| • | Relationale Datenorganisation (rel. Datenbanken) |
Eine Datenbank kann aus mehreren Dateien bestehen, die jeweils in Datensätze untergliedert sind. Jeder Satz wird durch den Satztyp deklariert, d.h. festgelegt, aus welchen Komponenten er besteht und welcher Datentyp diesen Komponenten zugeordnet ist. Eine Datei besteht immer aus Sätzen des gleichen Typs. Die Komponenten eines Satzes heißen Felder (Datenfelder oder Datenelemente) und können unterschiedliche Datentypen besitzen.

(Quelle: M.Schreiber)
Zusammenhang zwischen Datenbank (database), Datei (table), Datensatz (record), Datenfeld (field) und Datentyp (type)
Das Dreischichtenmodell
Für die Planung und den Entwurf von Datenstrukturen innerhalb eines Datenbankmanagementsystems (DBMS) geht man üblicherweise in drei Schritten vor.
Konzeptuelle (logische) Ebene
Auf der konzeptuellen Ebene wird unabhängig von den Anforderungen der DV-Anlage eine logische Gesamtsicht der Daten festgelegt. Dieses konzeptuelle Schema wird durch einen Datenbankadministrator festgelegt.
Beispiel: Für eine Bibliotheksanwendung werden die Datenstrukturen für die Bücher, die Benutzer und die Ausleihdaten konzipiert und die dazugehörigen Felder und Dateitypen festgelegt.
Regeln:
| • | Entitäten genau herausfinden |
| • | nie Daten redundant (in mehreren Tabellen) halten! |
Externe Ebene
Die Daten werden so dargestellt, wie die Benutzer oder die Programme sie benötigen. (Ansichten)
Beispiel: Für die Bibliotheksmitarbeiter gibt es zum Einarbeiten der Bücher andere Sichten (und Zugriffsrechte) als für Studierende, die Literatur suchen und ausleihen wollen.
Interne Ebene
Die Daten werden so auf den Speichern organisiert, daß die Zugriffsanforderungen der verschiedenen Benutzer erfüllt werden können.
Beispiel: Für die Autoren- und für die Titel-Felder werden zur Beschleunigung der Suchen Indexe erstellt.
Zwischen den Ebenen werden die Transformationsregeln festgelegt, die die Unabhängigkeit der einzelnen Ebenen gewährleisten.
Relationale Datenbanken
Das Konzept der relationalen Datenbanken wurde gegen Ende der 60er Jahre vom IBM Mitarbeiter Dr. E. F. Codd entwickelt und hat sich seitdem unaufhaltsam verbreitet. In der traditionellen Dateiverarbeitung (hierarchische DB und netzwerkorientierte DB) operiert man auf einzelnen Datenbanken, während in den relationalen Datenbanken vom Konzept her auf ganzen Dateien bzw. Tabellen gearbeitet wird.
Relationale Datenbanken sind einfach aufzubauen und sehr leistungsfähig in der Verknüpfung und Verarbeitung der Daten.
Um aus verschiedenen Tabellen eine relationale Datenbank zu machen, bedarf es der Befolgung bestimmter Regeln:
Tabellen Eigenschaften
| • | Das Grundkonzept der relationalen Systeme ist die Tabelle. |
| • | Jede Tabelle besteht aus Zeilen (Datensätzen) und aus einer festen Anzahl von Spalten (Attributen). Eine Tabelle darf also lediglich einen Datensatztyp beinhalten. |
| • | Der Tabelle ist eine Name zugeordnet (Überschriftszeile). |
| • | Jedes Datenfeld darf nur einen einzigen Wert aufweisen. |
| • | Jeder Datensatz darf in einer Tabelle nur einmal vorkommen (Duplikate sind nicht erlaubt) |
| • | Die Reihenfolge der Sätze in einer Tabelle ist unbestimmt, das heißt, die Datensätze dürfen in beliebiger Folge auftreten; |
Neue Tabellen können aufgrund von Übereinstimmungen von Feldinhalten derselben Domäne in zwei bestehenden Tabellen erzeugt werden. Die Bildung neuer Tabellen aus bestehenden heraus ist eine der zentralen Funktionen relationaler Datenverarbeitung.
Eigenschaften der Attribute
Mit Festlegung eines Datentyps für jedes Attribut kann erreicht werden, dass
| • | die Daten effizienter abgespeichert werden können (Y2K-Problem) |
| • | datentypspezifische Sortierungen festgelegt werden können (Sigrid |
| • | unterschiedliche Verknüpfungen bei verschiedenen Datentypen verwendet werden können |
Entity-Relationship-Modell
Bei relationalen Datenbanken ist beim Entwurf der Relationen zu beachten, dass die Daten "sauber" strukturiert sind, damit während der Verarbeitung keine Redundanzen und Anomalien entstehen. Diese Formen der Strukturierung werden als Normalformen bezeichnet.
Als Entwurfsformalismus hat sich das sogenannte Entity-Relationship-Modell etabliert, in der die Daten und ihre Beziehungen untereinander grafisch dargestellt werden.
Von zentraler Bedeutung sind die Beziehungen die zwischen den Tabellen konstruiert werden.
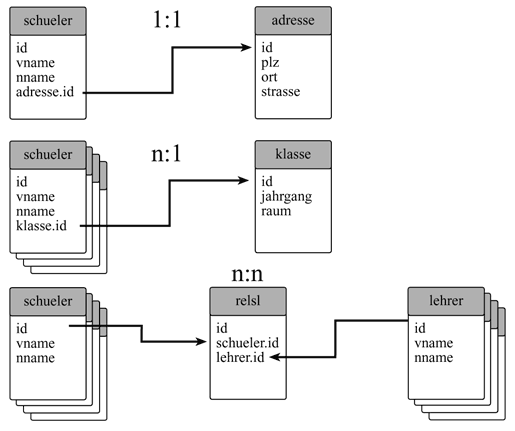
| • | 1:1 Wenn eine Tebelle eindeutig mit einer anderen in einer 1:1-Beziehung steht (ein Schüler : eine Adresse) kann direkt über den Primärschlüssel in einer der beiden Tabellen die Verbindung hersestellt werden. |
| • | 1:n / n:1 Kann eine Tabelle mit mehreren anderen in Beziehung stehen (eine Klasse : n Schüler) kann ebenfalls über den Primärschlüssel, allerdings zwindend in der n-Tabelle (Schüler) die Verbindung hergestellt werden. |
| • | n:n Stehen beide Tabellen in vielfacher Beziehung miteinander (n Lehrer : n Schüler) muß eine Kreuztabelle gebildet werden, die die Primärschlüssel beider Tabellen miteinander relationiert. |
In der Regel enthält jeder Satz einen Schlüssel, d.h. ein Datenfeld, mit der der Datensatz identifiziert werden kann. Mit Hilfe dieses Schlüssels können auch Such- und Sortierroutinen erheblich beschleunigt werden. Ein Schlüssel, der aus einem Attribut oder einer Attributskombination besteht und dem genau einem Datensatz zugeordnet ist, wird als Primärschlüssel (primary key) bezeichnet. Ein Sekundärschlüssel (foreign key) kann zu mehreren Datensätzen führen.